We propose a system for rearranging objects in a scene to achieve a desired object-scene placing relationship, such as a book inserted in an open slot of a bookshelf. The pipeline generalizes to novel geometries, poses, and layouts of both scenes and objects, and is trained from demonstrations to operate directly on 3D point clouds. Our system overcomes challenges associated with the existence of many geometrically-similar rearrangement solutions for a given scene. By leveraging an iterative pose de-noising training procedure, we can fit multi-modal demonstration data and produce multi-modal outputs while remaining precise and accurate. We also show the advantages of conditioning on relevant local geometric features while ignoring irrelevant global structure that harms both generalization and precision. We demonstrate our approach on three distinct rearrangement tasks that require handling multi-modality and generalization over object shape and pose in both simulation and the real world.
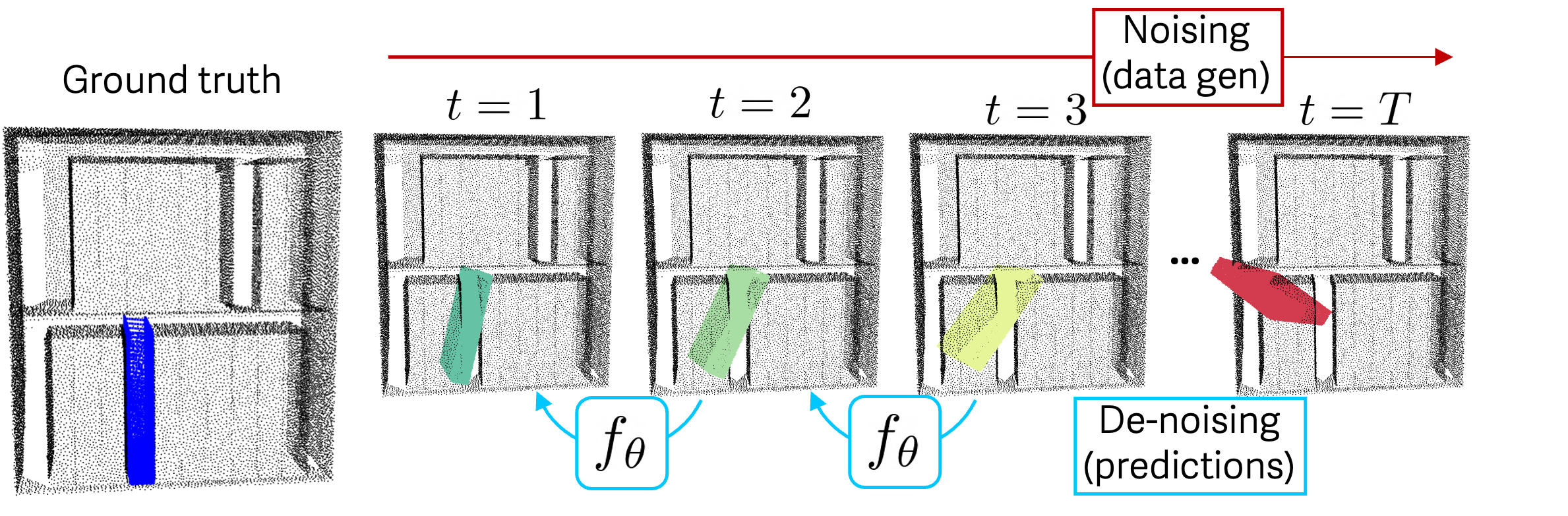
Test-time Inference via Iterative Pose De-noising
Iterative pose de-noising for unseen simulated objects at test-time. Starting from diverse initial guess configurations of the objects relative to the scene, the inference process converges to a diverse set of final output rearrangement solutions.
Book/Bookshelf
Mug/Rack-multi
Can/Cabinet
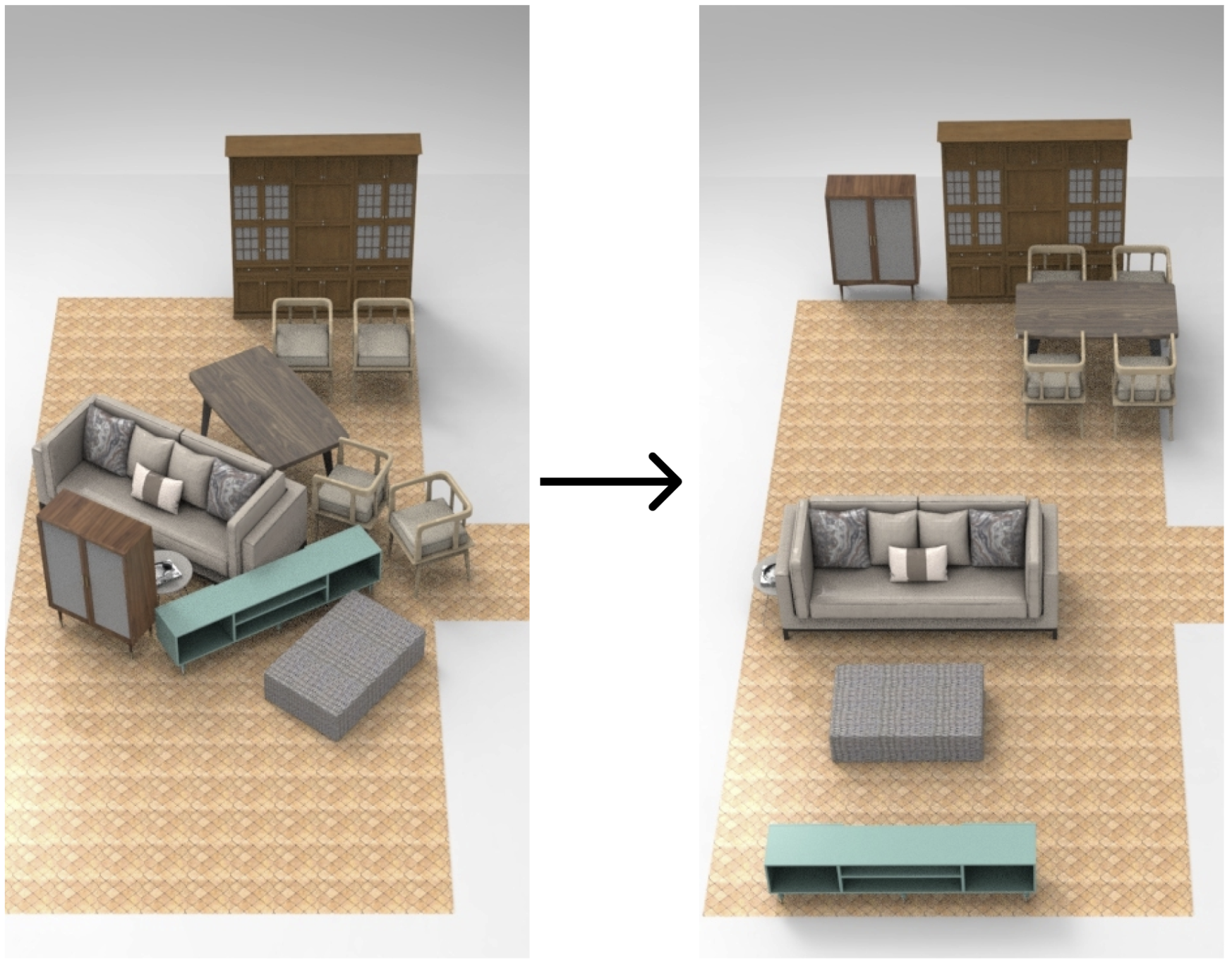
Real-world Multi-modal Rearrangement via Pick-and-Place
Rearrangement in the real world using the Franka Panda arm. Each task features scene objects that offer multiple placement locations. RPDiff is used to produce a set of candidate placements and one of the predicted solutions is executed. Multiple executions in sequence show the ability to find multiple diverse solutions. Our neural network is trained in simulation and directly deployed in the real world (we do observe some performance gap due to sim2real distribution shift).
Book/Bookshelf
Mug/Rack-multi
Can/Cabinet
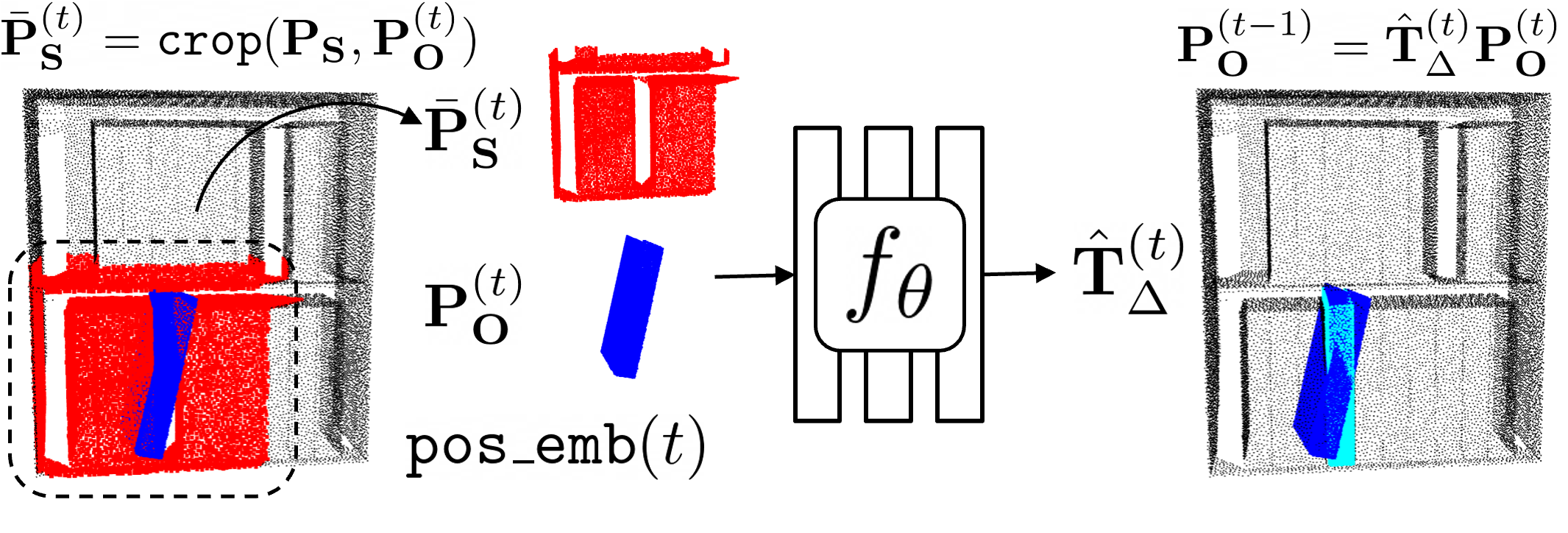
Training by perturbing object-scene point clouds and predicting corrective SE(3) transforms
We train on examples of point clouds showing properly configured object-scene pairs, obtained from procedurally generated rearrangement demonstrations on simulated objects. Training targets are generated by creating object point clouds with sequences of perturbation transforms applied. The network is trained to take in the noised object-scene point cloud and predict an SE(3) transform to apply to the object that takes a step back toward the original configuration. We crop the scene point cloud to improve generalization and precision by ignoring faraway details that are irrelevant for prediction and re-use features that describe local scene geometry across instances and spatial regions.
Our Related Projects
Check out our related projects on the topic of object rearrangement and local scene conditioning



External Related Projects
Check out other projects related to diffusion models, iterative prediction, and rearrangement


Paper
